
Inhoud
Bekijk hier de opname van de LIBISnet-workshop over dit thema (28 februari 2023)
Wat zijn de FRBR- &
dedup-processen?
FRBR en dedup zijn twee mechanismen die in
Limo afzonderlijke Alma-records verzamelen
zodat gebruikers records die 'samenhoren'
ook als groep terugvinden in de
zoekresultatenlijst. Beide processen
werken volgens een verschillend
basisprincipe.
Het FRBR-proces (of
FRBRization)
vertrekt vanuit het FRBR-model. Dat staat
voor Functional Requirements for
Bibliographic records. Binnen dit
model is het FRBR-proces bedoeld om
gelijkaardige records te groeperen:
het gaat dan, in FRBR-termen, om het
samenbrengen van de verschillende
manifestaties en expressies van hetzelfde
werk. In meer 'klassieke' catalografische
termen, kan je stellen dat FRBR bedoeld is om
de verschillende edities van een bepaalde
tekst te verzamelen en als een overzichtelijk
geheel aan de gebruiker te presenteren.
Het dedup-proces (of deduplication)
zorgt ervoor dat gelijke records worden
samengesmolten. Het gaat dan niet
over records die verschillende edities
beschrijven maar om records die dezelfde
editie beschrijven. Verschillende scenario's
leiden ertoe dat in Limo meerdere records voor
dezelfde editie aanwezig kunnen zijn:
- omdat in Alma 2 afzonderlijke records
worden gemaakt voor de fysieke (P) en
elektronische (D/E) versie van eenzelfde
editie.
- omdat in Limo records samenkomen uit
verschillende bronnen (Alma, Lirias)
waartussen overlap bestaat en eenzelfde
editie dus in twee of meer bronbestanden
beschreven is.
- omdat (al dan niet per ongeluk) eenzelfde
editie meerdere bibliografische records
kreeg in Alma.
De FRBR- en dedup-processen werken niet op
alle records die in Limo getoond
worden:
- FRBR & dedup werken op de records die
vanuit Alma in Limo getoond worden
(uitgezonderd bepaalde groepen, cf.
infra).
- FRBR & dedup werken ook op records die
rechtstreeks in Limo worden ingeladen (bv.
Lirias-records).
- FRBR & dedup werken ook tussen beide
vorige groepen (de lokale records): Alma
en Lirias-records worden dus ook onderling
samengevoegd volgens FRBR- en
dedup-principes.
- records uit de Central Discovery Index
(CDI) worden onderling wel volgens dedup
samengevoegd, maar niet volgens
FRBR.
- er is ook geen FRBR, noch dedup tussen
records lokale records en records uit de
CDI.
Hoe worden FRBR en dedup zichtbaar in
Limo?
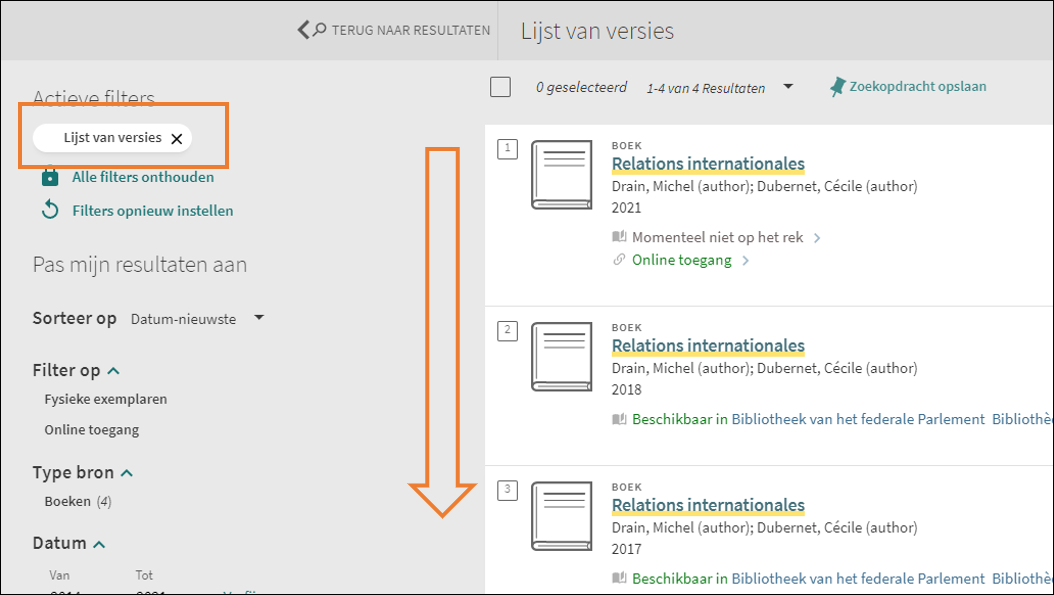
FRBR brengt gelijkaardige records samen in een FRBR-groep. Deze zijn in een
zoekresultatenlijst duidelijk herkenbaar aan
het specifieke icoontje, de aanduiding Meerdere versies i.p.v. een specifiek
documenttype en de aanduiding [x] versies
gevonden. Bekijk alle versies onder de
titel.

Records die door het dedup-mechanisme zijn
samengesmolten zijn in de
zoekresultatenlijst
(met opzet) minder herkenbaar. Ze worden net
als andere records getoond
als 1 zoekresultaat. Aan dit
zoekresultaat
wordt dan wel alle inventory gekoppeld
van de samengevoegde records. Een
record
waarbij zowel verwezen wordt naar beschikbare
fysieke exemplaren als naar een elektronische
toegang, zal dus bijna altijd een dedup-groep
van 2 of meer samengesmolten records
zijn.

Bij dedup is er op het niveau van
het
bibliografisch record geen samensmelting. Limo
'kiest' 1 van de records in de dedup-group als preferred record volgens volgende
principes:
- als je in je zoekopdracht een zoekterm
opgaf die slechts in 1 van de records
voorkomt, wordt dit record als preferred
record getoond. Je krijgt dus steeds het
voor jou meest relevante record te
zien.
- is er op dit punt geen verschil te maken,
dan geeft Limo de voorrang aan de fysieke
versie.
Belangrijk: de samengesmolten records van een
dedup-groep zijn opzoekbaar met alle
zoektermen uit alle records. Ook in de facets
worden de termen van de verschillende records
getoond.
Er is ook een methode om in Limo met
zekerheid
na te gaan of een zoekresultaat een
dedup-groep toont of niet:
- klik het zoekresultaat aan zodat het
record in detail wordt weergeven in
Limo.
- voeg in de adresbalk van je browser
achteraan
de url &ShowPnx=true toe.
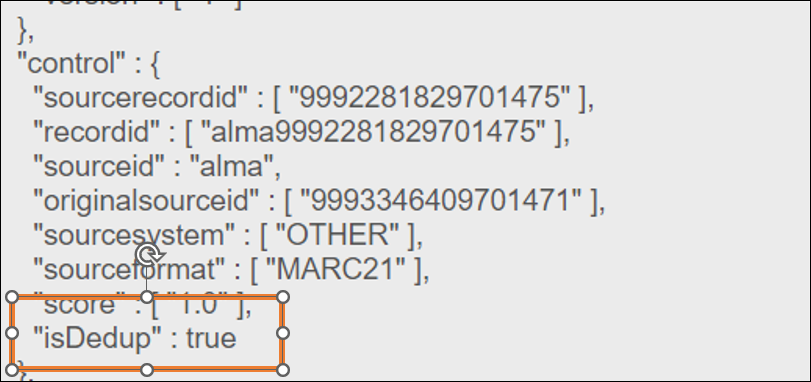
- je ziet nu het PNX-record (de 'achterkant'
van
het mooi vormgegeven Limo-record).
- zoek in de control-sectie naar het
label isDedup. Als daarachter true staat, heb je te maken
met een
dedup-groep.
Hoe bepaalt Limo welke records in
FRBR- of dedup-groepen horen?
Beide mechanismen werken op een gelijkaardige
manier: losse metadata-elementen uit de
bronrecords in Alma, Lirias, CDI, ...
(partial keys) worden
volgens
vaste regels gecombineerd tot complete
keys. Zo krijgt elk
record een set van complete keys die dan
kan vergeleken
worden met de sets van andere
records. Zodra één van de complete keys in 2
of meerdere records exact overeenkomt, spreken
we van een match en worden de records
samengebracht in een FRBR- of
dedup-groep.
Voor het FRBR-mechanisme is de opbouw van de
keys vrij eenvoudig:
- als het record een tag 100, 110 of 111
bevat wordt deze tag gecombineerd met de
volledige titel (245) tot de unieke
FRBR-key voor dat record. Zowel
auteursnaam als titel worden wel
vereenvoudigd zodat bv. leestekens geen
invloed hebben op de opmaak van de
FRBR-key.
- Als er geen tag 100, 110 of 111 in het
record zit, worden er FRBR-keys gemaakt
voor alle combinaties van de tags 700, 710
en 711 in het record met de volledige
titel (245). Een record zonder tag 100,
110 of 111 maar met 2 700- en 1 710-tag
zal dus 3 FRBR-keys krijgen.
Voor dedup is de opbouw van de keys een stuk
complexer. Dat komt omdat er naast
auteursnamen en titels ook nog heel wat andere
metadata-elementen worden opgenomen in de
dedup keys: identifiers uit tag 035,
ISBN, ISSN, datum van uitgave,
uitgever. Een voorbeeld: de meest uitgebreide
dedup complete key maakt volgende
combinatie:
- de volledige titel uit tag 245
- het publicatiejaar (uit 008 of als dat
niet is ingevuld uit 260 $$c of als dat
niet aanwezig is uit 264 $$c)
- de uitgever (260 $$b > 264 $$b)
- de paginering (300 $$a)
- De hoofdauteur (uit 100 of 110)
Een volledig overzicht van alle partial keys en
de manier waarop ze tot complete keys in
elkaar worden
gepuzzeld, is beschikbaar op volgende
webpagina: Understanding the Dedup
and FRBR processes.
Hoe krijg je als catalograaf zicht op
wat FRBR/dedup met 'jouw' record zal
doen?
FRBR en dedup zijn geen 'toverdozen'. Ze
verwerken volgens logische principes de
gegevens uit (Alma-)records en vergelijken
deze met andere records. Het is ook mogelijk
om in Alma al zicht te krijgen op:
- de set van complete keys die voor
een bepaald record wordt aangemaakt.
- de vergelijking van de sets van
1 record met die van andere records.
Zo vind je antwoorden op de vragen of 'jouw'
record in een FRBR- of dedup-groep is
ondergebracht, welke andere records tot die
groep behoren en op basis van welke gegevens
ze werden samengebracht/samengesmolten.
De tool die we daarvoor gebruiken is de Dedup and FRBR Test
Utility. Deze open
je als volgt:
- klik onderaan links het Alma scherm op Configuration.
- klik nu in de linkermenubalk op Discovery.
- klik in de lijst van functies onder Other op Dedup and FRBR Test
Utility.
Deze tool neemt nu zowat het hele Alma-scherm
in. Bovenaan zie je dat de tool is ingedeeld
in twee tabs voor de
twee verschillende
manieren waarop je deze tool kan
gebruiken.
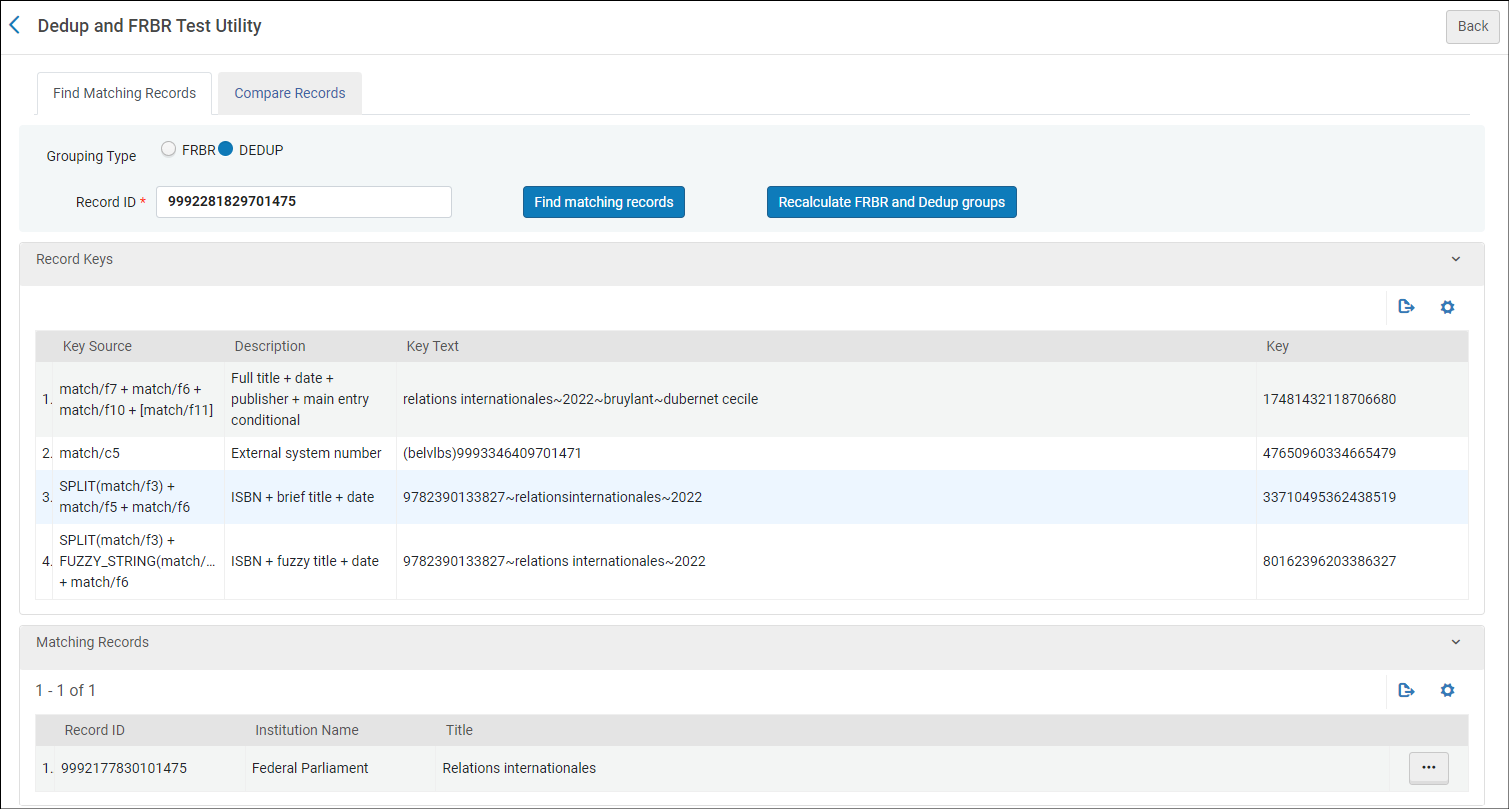
Find matching records
Hier kan je het MMS ID van 1 record ingeven
en
vervolgens kijken of het record tot een
FRBR-
of dedup-groep behoort:
- plak het MMS ID in het vakje achter Record
ID. Dit mag zowel het MMS ID van
het
record in de Network Zone zijn (eindigend
op 1471) als het MMS ID van het record in
jouw Institution Zone.
- kies of je de vergelijking wil
zoeken naar matching records volgens de
FRBR-regels of volgens
dedup-principes.
- klik op de knop Find matching
records.
- de tool toont nu eerst de set van complete
keys die voor het record
werden samengesteld. Vooral interessant
zijn de kolom met de Description waarin de opbouw van elke key wordt
getoond (welke metadata-elementen er in
elke key worden opgenomen) en de kolom Key waarin dan de juiste
samenstelling van die key voor het
gezochte record wordt getoond.
- als er andere records zijn die matchen met
het record dat je
zocht, worden deze onderaan opgelijst.
Achter elk record is een
...-knop zichtbaar. Klik erop om ofwel een
lijst te krijgen van de keys die beide
records delen (View mutual keys) of
van de hele key set van het record in
kwestie (View keys).

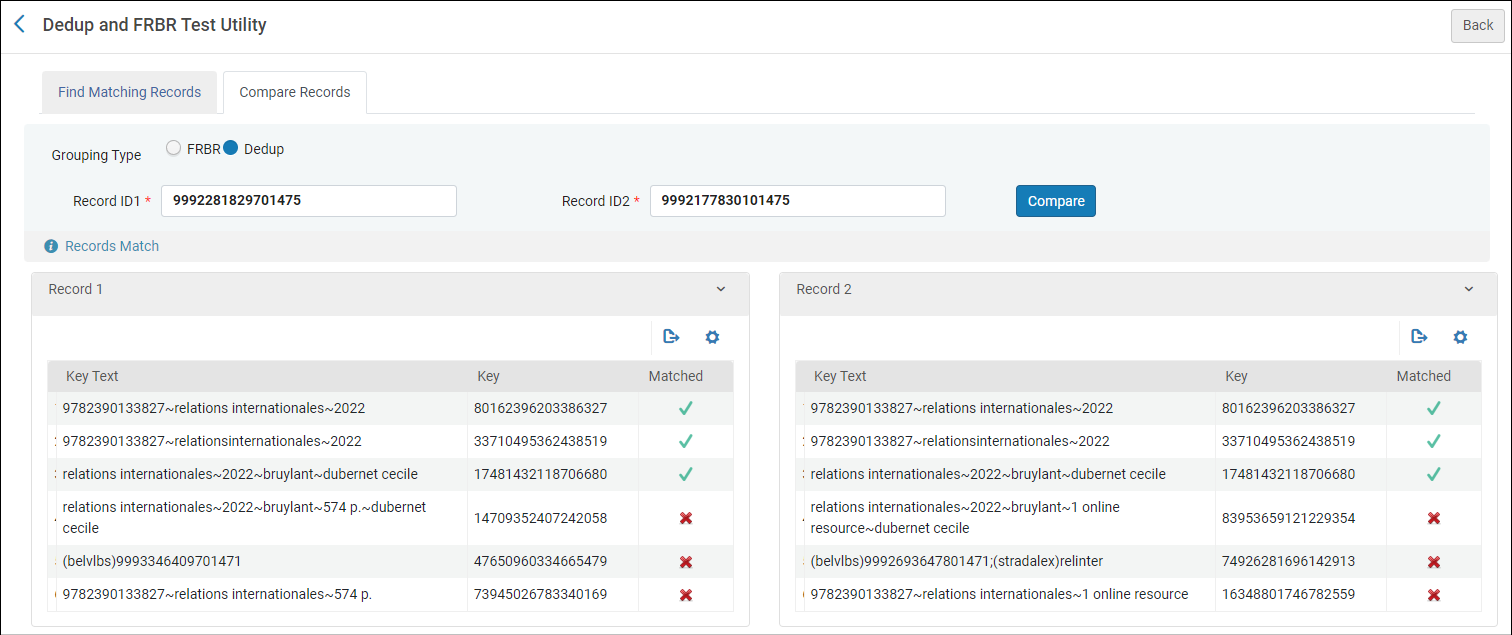
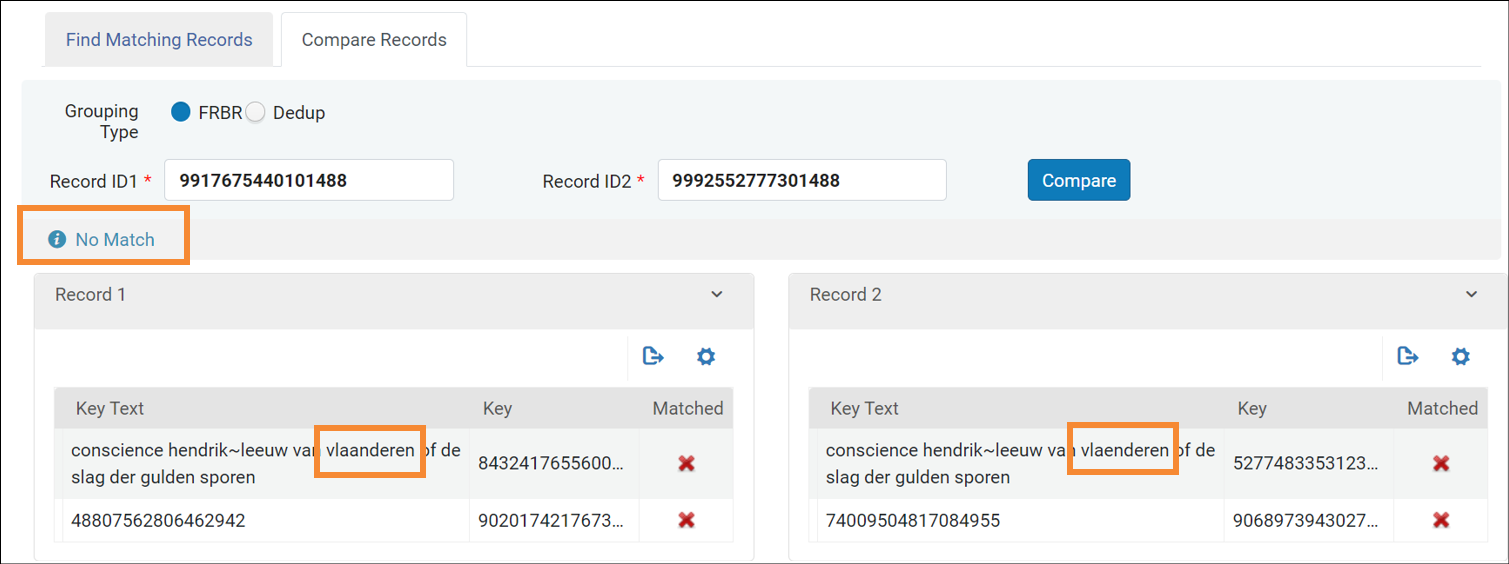
Compare records
Dit deel van de tool laat toe om 2 records
tegenover elkaar te zetten en de key sets
nauwkeurig te vergelijken.
- plak in de 2 vakken de MMS ID's van 2
records die je wil vergelijken. Ook hier
kunnen NZ en IZ MMS gebruikt worden en
zelfs door elkaar.
- klik op Compare.
- de key sets van beide records worden naast
elkaar gezet. Groene vinkjes en rode
kruisjes geven aan welke complete keys wel
resp. niet met elkaar overeenkomen.
Opgelet: bij nieuwe records kan je deze tool
pas gebruiken nadat het record voor een
eerste
keer definitief is opgeslagen
(Save). Pas dan
wordt het record in Alma geïndexeerd
en worden de geïndexeerde metadata-elementen
gebruikt om de key set op te bouwen en te
vergelijken met de al aanwezige key sets. Het
is dus niet mogelijk om tijdens het opstellen
van een record al te 'proberen' of het record
zal matchen of niet.
Hoe kunnen we de werking van FRBR en
dedup aanpassen?
Er zijn twee manieren waarop we op niveau
van
configuratie de werking van de FRBR- en
dedup-mechanismes kunnen
aanpassen.
Ten eerste kan er gesleuteld worden aan de
manier waarop de key sets worden
opgebouwd:
bestaande complete keys kunnen
ge(des)activeerd worden en het is ook mogelijk
om op basis van de partial keys nieuwe
complete keys te laten opbouwen en deze toe te
voegen aan de key set. De out-of-the-box
configuratie van PrimoVE die wordt toegepast
in Limo werd zoveel mogelijk aangepast om de
werking van de FRBR- en dedup-processen te
reproduceren zoals die bestond in Limo classic (op basis van Primo). Toch zijn
er nog enkele verschillen zoals bv. het
gebruik van tag 035 als een belangrijk element
in het dedup-mechanisme. Deze werd niet
gebruikt in Limo classic.
Verdere aanpassingen van deze configuratie
zijn
nog mogelijk maar moeten heel goed
overwogen
worden:
- een aanpassing om een bepaald effect te
bereiken (bv. dat bepaalde types records
wel of niet deduppen) heeft vaak
ongewenste neveneffecten op andere
records.
- een aanpassing in de configuratie heeft
niet meteen effect in Limo: daarvoor
moeten de betrokken records geherindexeerd
worden en dit kan enkel manueel record per
record (zie verder) of op aanvraag door Ex
Libris worden gedaan.
Ten tweede is het mogelijk om regels te
bepalen
die het dedup- en/of FRBR-mechanisme voor
bepaalde groepen van records
uitschakelen. Op
dit moment wordt dit systeem op twee manieren
gebruikt:
- voor records die oude drukken,
handschriften, kaarten en grafisch
materiaal (images) beschrijven is
zowel het FRBR- als dedup-mechanisme
onderdrukt. Deze records zullen dus steeds
elk afzonderlijk op een
Limo-zoekresultatenlijst
verschijnen.
- wanneer een catalograaf in het
bibliografisch record de tag 900 $$a NO
DEDUP toevoegt, dan zal het
dedup-mechanisme niet ingrijpen op het
record. FRBR werkt wel en het record kan
dus wel in een een FRBR-groep op de
zoekresultatenlijst terechtkomen [noot:
dit mechanisme werkt omwille van
technische problemen momenteel nog niet.
Er wordt met Ex Libris naar een oplossing
gezocht].
Hoe kan je als catalograaf de impact
van dedup en/of FRBR op een specifiek record
manipuleren?
Soms merk je in Limo op dat twee of meer
records door het FRBR- of dedup-mechanisme
worden samengebracht of samengesmolten (of
juist niet) en heb
je daar vragen bij. De FRBR and
Dedup test
utility helpt antwoorden en
oplossingen te zoeken. Je werkt best
steeds in
drie stappen.
Analyse
Met de test utility kan je nagaan waarom
2 of meer records matchen (of juist niet) en
de oorzaak achterhalen: gaat het om foutjes of
onvolledigheden in de records, werkt
FRBR/dedup hier zoals verwacht/gewenst?
Verzamel allereerst de MMS ID's van de records
die je wil vergelijken (tip: kopieer ze even
naar bv. Notepad). Gebruik vervolgens de
test utility om deze records naast elkaar
te
zetten. Vooral de Compare
records-functie is daarbij erg handig.
Wanneer twee records onverwacht niet matchen
is het natuurlijk zoeken naar de verschillen
tussen de key sets. Wanneer twee records
onverwacht wel matchen, bekijk je vooral de
complete keys die overeenkomen (groen
vinkje).
Op basis van die vergelijking moet je
beoordelen of het al dan niet groeperen
door
FRBR en dedup terecht of onterecht
is.
FRBR en dedup-(niet)groepering is terecht
wanneer:
- alle betrokken bibliografische records volledig zijn ingevoerd. Let
daarbij
vooral op de tags 008, 035, 020, 022, 245,
264, 300, 1XX en 7XX. Dit zijn immers de
velden die door FRBR en dedup worden
gebruikt om de key sets op te
bouwen.
- de bibliografische records in Alma zijn correct volgens de regelgeving
ingevoerd.
Ze bevatten geen (tik)fouten en alle
regels zijn toegepast. Heel belangrijk is
bv. de correcte identificatie en invoer
van
een eventuele hoofdauteur in tag 100/110.
Voor auteursnamen in het algemeen
(100/110/700/710) geldt dat de invoer via
authority control een grote hulp is om de
consistente invoer (en dus de correcte
werking van FRBR/dedup) te
verzekeren.
Wanneer FRBR en dedup op basis van correcte
gegevens key sets opbouwen die vervolgens
al dan niet voor matches zorgen, wordt de
werking van FRBR en dedup ook als correct
beschouwd.
Omgekeerd wordt het ingrijpen van FRBR en
dedup als niet-correct beschouwd wanneer
dit gebeurt op basis van onvolledige
records of records die fouten
bevatten.
Een speciaal aandachtspunt hierbij zijn
documenten die zo weinig bibliografische
informatie bevatten dat het
quasi-onmogelijk is om voldoende rijke
bibliografische records op te stellen
(denk aan grijze literatuur met generiek
titels, ontbreken van auteursnamen,
publicatieplaats, -jaar en uitgever
...).
In dat laatste geval moet dus bekeken
worden of we door aanpassingen aan de
bibliografische records de werking van
FRBR en/of dedup kunnen corrigeren.
Verbeteren en aanvullen of dedup
blokkeren
Het grootste deel van onterechte
(niet)-werking van FRBR en dedup kan
opgelost worden door de bib records op
punt te stellen:
- kijk het record goed na en verbeter
fouten.
- vul ontbrekende bibliografische
gegevens toe indien mogelijk.
- vooral bij oudere records is het vaak
nodig om het record 'in regel te
stellen' met de huidige regelgeving.
Dat geldt in het bijzonder voor het
onderscheiden van een hoofdauteur in
tag 100/110 én voor het aanpassen van
auteursnamen naar de hoofdvorm van het
authority record (dus tags
100/110/700/710 via F3 opzoeken in het
authority bestand).
Opgelet: het is niet de bedoeling dat we de
kar voor het paard gaan spannen en
aanpassingen doorvoeren die ingaan tegen
de regelgeving met het doel om FRBR/dedup
te doen werken zoals we dat
wensen/verwachten. Elk record wordt
afzonderlijk opgesteld volgens de
vastgelegde regels. Een
voorbeeld: een oude editie van
Consciences De leeuw van
Vlaenderen zal niet in een
FRBR-groep terechtkomen met een recente editie
met licht anders gespelde titel De
leeuw van Vlaanderen. Maar
beide records zijn elk op zich correct
opgesteld (de titel werd immmers volgens
basisprincipe take what you see overgenomen uit beide edities) en dus
beschouwen we de
niet-groepering door FRBR als
correct.
In (zeer) uitzonderlijke gevallen kan een
catalograaf beslissen om het
dedup-mechanisme te blokkeren voor een
specifiek record door in dat record de tag
900 $$a NO DEDUP in te voeren. Dat zal
dan
voornamelijk nodig zijn in de eerder
genoemde bibliografische records voor
documenten met zeer beperkte/generieke
bibliografische gegevens. Dergelijke
records worden soms onterecht in een FRBR-
of dedup-groep opgenomen. Om aan collega's
duidelijk te maken wat er aan de hand is,
voeg je in 900 $$b ook een korte
'motivering' toe waarom de NO
DEDUP-sleutel noodzakelijk was.
De FRBR/dedup-groepering voor een record
herberekenen
Een of meerdere records verbeteren en
aanvullen of zelfs een blokkerende 900 $$a
NO DEDUP toevoegen is op zich niet
genoeg om
ook het beoogde effect te bereiken in
Limo. FRBR- en dedup-groepen zijn immers
heel 'hardnekkig' en het is daarom
noodzakelijk om
manueel de herberekening van deze groepen
voor gewijzigde records op te starten.
Ook
hiervoor hebben we de FRBR and Dedup
Test
utility nodig.
- zorg dat je het MMS ID van minstens
één van de bewerkte records bij de
hand hebt (bv. gekopieerd naar
Notepad) en open de test utility.
- plak het MMS ID op de tab Find
matching records in het juiste
vak en klik op de knop Recalculate
FRBR and Dedup groups.
- na een korte tijd wachten verschijnt
de boodschap dat de job gestart
is.
- even later zal je bij een nieuwe test
in de tool vaststellen dat de key set
van het record is aangepast en dat ook
de lijst van matching records
aangepast is. Als alles correct
verloopt zie je daar nu wel (of juist
niet) de records waarmee het bewerkte
record moet (of niet mag)
matchen.
- op de aanpassing in Limo is het soms
nog even langer wachten maar ook deze
zal na een tijd gelijk lopen met de
resultaten van de test utility.
Samenvattend: tips voor
catalografen
Om af te sluiten nog een aantal tips die
catalografen kunnen gebruiken om bij het
opstellen van nieuwe records ervoor te zorgen
dat FRBR en dedup correct zullen werken. De
meeste zijn vanzelfsprekend:
- werk een record eerst zo volledig
mogelijk
uit voor je het een eerste keer
definitief
opslaat (Save). Op die manier zal
de
indexering en de indeling in FRBR- en
dedup-groepen ook gebeuren op basis van
het volledige record. De automatische
bewaarfunctie in Alma zorgt ervoor dat ook
voorlopig werk niet verloren gaat.
- pas de regels die bepalen of er een
hoofdauteur in 100 of 110 kan worden
ingevoerd en - bij meerdere
'kandidaten' -
hoe je beslist wie dat dan moet zijn,
correct toe. De aanwezigheid van
een main heading (een tag 1XX)
weegt
immers zwaar
door in FRBR- en dedup-keys. Meer
informatie: Personen en
corporaties in 100/110 of
700/710?
- voer auteursnamen in 1XX en 7XX-tags in
onder authority
control. Op die
manier zorgen we ervoor dat in de
bibliografische records steeds dezelfde
naamsvorm (de hoofdvorm uit het authority
record) wordt ingevoerd. Ook dat is
natuurlijk essentieel voor de correcte
werking van dedup en FRBR. Doe dit niet
enkel bij records die je opstelt op basis
van een template maar zeker ook bij
records die je via copycat uit een
externe catalogus in Alma opneemt.
- Duplicate record is geweldig
handig
maar vraagt in deze context ook extra
aandacht: denk er steeds aan om de
035-tags uit het gekopieerde record te
verwijderen. Een ander punt waar het wel
eens misgaat: vergeet niet om de datum van
publicatie aan te passen, niet alleen in
tag 264 $$c maar ook in tag 008. Het is
immers die waarde die primair door dedup
wordt gebruikt in de opbouw van de
keys.
- Bijzonder voor bibliotheken waar i.f.v.
acquisitie gewerkt wordt met
zogenaamde PRECAT-records:
voorlopige bib records die worden
aangemaakt om een nieuwe publicatie via
Alma te kunnen bestellen. Deze
PRECAT-records zijn vaak nog onvolledig en
het is dus mogelijk dat de indeling in
FRBR/dedup-groepen bij opslaan van dit
voorlopige record niet helemaal juist
gaat. Deze records worden dan na levering
van de nieuwe aanwinst catalografisch op
punt gesteld maar deze wijzigingen in het
Alma-record triggeren dus niet
automatisch een herberekening van de FRBR-
en dedup-indeling. Het wordt daarom
aangeraden om na de afwerking manueel een Recalculate op te starten: je kan
het NZ MMS ID eenvoudig kopiëren uit de
tag 001 en met enkele clicks de Test
Utility opstarten, het MMS ID plakken en
de knop Recalculate FRBR and dedup
groups aanklikken.
Colofon
Laatst gewijzigd op 28.02.2023